
Аннотация
Это вторая часть цикла статей, посвященных свойствам и применению сверточных нейронных сетей (CNN), которые в основном используются для распознавания образов и классификации объектов. В первой статье «Введение в сверточные нейронные сети: Что такое машинное обучение? – Часть 1» мы показали, чем классическая линейная программа, выполняемая на микроконтроллере, отличается от CNN и в чем ее преимущества. Мы обсудили сеть CIFAR, с помощью которой можно классифицировать на изображениях такие объекты, как кошки, дома или велосипеды, или выполнять простое распознавание голосовых образов. Во второй части рассказывается о том, как можно обучать эти нейронные сети для решения задач.

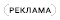
Процесс обучения нейронных сетей
Сеть CIFAR, рассмотренная в первой части серии, состоит из различных слоев нейронов, как показано на Рисунке 1. Данные изображения размером 32 × 32 пикселя подаются в сеть и проходят через слои сети. Первым шагом в CNN является обнаружение и исследование уникальных особенностей и структур объектов, которые нужно различать. Для этого используются матрицы фильтров. Когда нейронная сеть, такая как CIFAR, спроектирована разработчиком, эти матрицы фильтров изначально еще не определены, и на этом этапе сеть еще не способна обнаружить паттерны и объекты.
 |
|
| Рисунок 1. | Архитектура сверточной нейронной сети CIFAR. |
Для этого сначала необходимо определить все параметры и элементы матриц, чтобы получить максимальную точность обнаружения объектов или минимизировать функцию потерь. Этот процесс известен как обучение нейронной сети. Для обычных приложений, описанных в первой части этой серии, сети обучаются один раз во время разработки и тестирования. После этого они готовы к использованию, и их параметры больше не нужно настраивать. Если система классифицирует знакомые объекты, дополнительное обучение не требуется. Обучение необходимо только в том случае, если система должна классифицировать совершенно новые объекты.
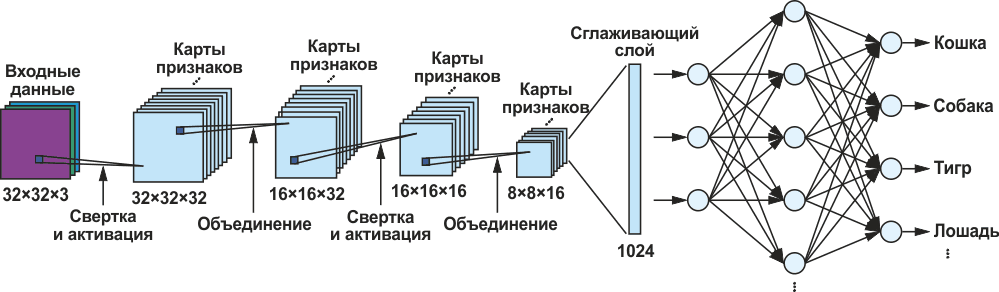
Для обучения сети необходимы обучающие данные, которые позже будут использоваться для оценки точности сети. Например, в нашем сетевом наборе данных CIFAR-10 данные представляют собой набор изображений, относящихся к десяти классам объектов: самолет, автомобиль, птица, кошка, олень, собака, лягушка, лошадь, корабль и грузовик (Рисунок 2). Однако – и это самая сложная часть всего процесса разработки приложения ИИ – эти изображения должны быть названы перед обучением CNN. Процесс обучения, о котором пойдет речь в этой статье, работает по принципу обратного распространения ошибки: сети последовательно показывают множество изображений, и каждый раз одновременно передают целевое значение. В нашем примере это значение соответствует классу объекта. При каждом показе изображения матрицы фильтров оптимизируются таким образом, чтобы целевые и фактические значения для класса объекта совпадали. После завершения этого процесса сеть также может обнаруживать объекты на изображениях, которые она не видела во время обучения.
 |
|
| Рисунок 2. | Цикл обучения, состоящий из прямого и обратного распространения. |
Переобучение и недообучение
При моделировании нейронных сетей часто возникают вопросы о том, насколько сложной должна быть нейронная сеть, то есть сколько слоев она должна иметь или насколько большими должны быть ее матрицы фильтров. На этот вопрос нет простого ответа. В связи с этим важно обсудить вопросы переобучения и недообучения сети. Переобучение является результатом чрезмерно сложной модели, имеющей слишком большое количество параметров. Определить, слишком ли плохо или слишком хорошо модель предсказания подходит к обучающим данным, можно, сравнив потери обучающих данных с потерями тестовых данных. Если во время обучения потери низкие, а при предъявлении сети тестовых данных, которые ей никогда ранее не предъявлялись, они чрезмерно возрастают, это является сильным признаком того, что сеть запомнила обучающие данные вместо того, чтобы обобщить распознавание образов. В основном это происходит, когда сеть имеет слишком большой объем памяти для хранения параметров или слишком много сверточных слоев. В этом случае размер сети должен быть уменьшен.
Функция потерь и алгоритмы обучения
Обучение происходит в два этапа. На первом этапе сети предъявляется изображение, которое затем обрабатывается сетью нейронов и генерирует выходной вектор. Наибольшее значение выходного вектора представляет собой класс обнаруженного объекта, например собаки в нашем примере, который в случае обучения еще не обязательно должен быть правильным. Этот этап называется прямым распространением сигнала.
Разница между целевыми и фактическими значениями, возникающими на выходе, называется потерей, а соответствующая функция – функцией потерь. Все элементы и параметры сети входят в функцию потерь. Целью процесса обучения нейронной сети является определение этих параметров таким образом, чтобы функция потерь была минимальна. Эта минимизация достигается за счет процесса, в котором отклонение, возникающее на выходе (потери = целевое значение минус фактическое значение), подается назад через все компоненты сети до тех пор, пока оно не достигает начального слоя сети. Эта часть процесса обучения также известна как обратное распространение ошибки.
Таким образом, в процессе обучения образуется цикл, который пошагово определяет параметры матриц фильтров. Этот процесс прямого и обратного распространения повторяется до тех пор, пока значение потерь не опустится ниже предварительно заданной величины.
Алгоритм оптимизации, градиент и метод градиентного спуска
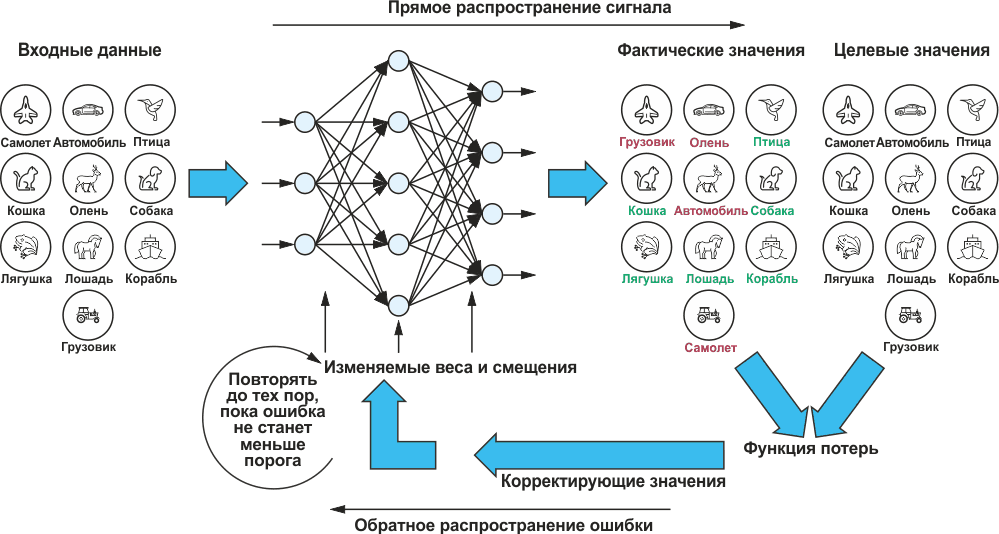
Чтобы проиллюстрировать процесс обучения, на Рисунке 3 показана функция потерь, состоящая всего из двух параметров x и y. Ось z соответствует потерям. Сама функция здесь не играет никакой роли и используется только для иллюстрации. Если мы более внимательно посмотрим на трехмерный график функции, то увидим, что она имеет глобальный и локальный минимумы.
 |
|
| Рисунок 3. | Различные пути к цели при использовании метода градиентного спуска. |
Для определения весов и смещений можно использовать большое количество алгоритмов численной оптимизации. Самый простой из них – метод градиентного спуска. Метод градиентного спуска основан на идее поиска пути, ведущего к глобальному минимуму от произвольно выбранной начальной точки функции потерь в пошаговом процессе с использованием градиента. Градиент, как математический оператор, описывает прогрессию физической величины. Он предоставляет в каждой точке нашей функции потерь вектор, также известный как вектор градиента, который ориентирован в направлении наибольшего изменения значения функции. Величина вектора соответствует величине изменения. В функции на Рисунке 3 вектор градиента будет направлен к минимуму в точке, расположенной в правом нижнем углу (красная стрелка). Величина была бы мала из-за плоской поверхности.
Ближе к пику в дальней области ситуация была бы иной. Здесь вектор (зеленая стрелка) направлен круто вниз и имеет большую величину из-за значительного перепада уровней рельефа.
При использовании метода градиентного спуска итерационно ищется путь, ведущий в долину с самым крутым спуском, начиная с произвольно выбранной точки. Это означает, что алгоритм оптимизации вычисляет градиент в начальной точке и делает небольшой шаг в направлении самого крутого спуска. В промежуточной точке градиент пересчитывается, и путь в долину продолжается. Таким образом, создается путь от начальной точки до точки в долине. Проблема заключается в том, что начальная точка не определена заранее, а должна быть выбрана случайным образом. На нашей двумерной карте внимательный читатель поместит начальную точку где-то в левой части графика функции. Таким образом, конец (например, синего) пути будет находиться в глобальном минимуме. Два других пути (желтый и оранжевый) либо намного длиннее, либо заканчиваются в локальном минимуме. Поскольку алгоритм оптимизации должен оптимизировать не просто два параметра, а сотни тысяч параметров, быстро становится ясно, что выбор начальной точки может быть правильным только случайно. На практике такой подход не представляется полезным. Это связано с тем, что в зависимости от выбранной начальной точки путь, а значит, и время обучения могут быть длинными, или же целевая точка может оказаться не в глобальном минимуме, и в этом случае точность сети снизится.
В результате за последние несколько лет было разработано множество алгоритмов оптимизации, позволяющих обойти две вышеописанные проблемы. Среди альтернативных вариантов – метод стохастического градиентного спуска, momentum, AdaGrad, RMSProp, Adam – вот лишь некоторые из них. Алгоритм, который используется на практике, определяется разработчиком сети, поскольку каждый алгоритм имеет определенные преимущества и недостатки.
Данные для обучения
Как уже говорилось, в процессе обучения мы предоставляем сети изображения, помеченные нужными классами объектов, такими как автомобиль, корабль и т. д. Для нашего примера мы использовали уже существующий набор данных CIFAR-10. На практике ИИ может применяться не только для распознавания кошек, собак и автомобилей. Если необходимо разработать новое приложение, например, для определения качества винтов в процессе производства, то сеть также должна быть обучена с помощью обучающих данных о хороших и плохих винтах. Создание такого набора данных может быть чрезвычайно трудоемким и длительным, и зачастую это самый дорогой этап в разработке приложения ИИ. После того как набор данных собран, он делится на обучающие и тестовые данные. Обучающие данные используются для обучения, как было описано ранее. Тестовые данные используются в конце процесса разработки для проверки работоспособности обученной сети.
Заключение
В первой части нашей статьи мы описали нейронную сеть, подробно рассмотрели ее устройство и функции. Теперь, когда мы определили все необходимые веса и смещения для функции, мы можем предположить, что нейронная сеть сможет работать правильно. В третьей части статьи мы протестируем нашу нейронную сеть для распознавания кошек, преобразовав ее в аппаратную. Для этого мы будем использовать микроконтроллер искусственного интеллекта MAX78000 с аппаратным ускорителем CNN, разработанный компанией Analog Devices.
 Купить MAX78000 на РадиоЛоцман.Цены
Купить MAX78000 на РадиоЛоцман.Цены


